知识库搜索方案和参数
本节会详细介绍 FastGPT 知识库结构设计,理解其 QA 的存储格式和多向量映射,以便更好的构建知识库。同时会介绍每个搜索参数的功能。这篇介绍主要以使用为主,详细原理不多介绍。
理解向量
FastGPT 采用了 RAG 中的 Embedding 方案构建知识库,要使用好 FastGPT 需要简单的理解Embedding向量是如何工作的及其特点。
人类的文字、图片、视频等媒介是无法直接被计算机理解的,要想让计算机理解两段文字是否有相似性、相关性,通常需要将它们转成计算机可以理解的语言,向量是其中的一种方式。
向量可以简单理解为一个数字数组,两个向量之间可以通过数学公式得出一个距离,距离越小代表两个向量的相似度越大。从而映射到文字、图片、视频等媒介上,可以用来判断两个媒介之间的相似度。向量搜索便是利用了这个原理。
而由于文字是有多种类型,并且拥有成千上万种组合方式,因此在转成向量进行相似度匹配时,很难保障其精确性。在向量方案构建的知识库中,通常使用topk召回的方式,也就是查找前k个最相似的内容,丢给大模型去做更进一步的语义判断、逻辑推理和归纳总结,从而实现知识库问答。因此,在知识库问答中,向量搜索的环节是最为重要的。
影响向量搜索精度的因素非常多,主要包括:向量模型的质量、数据的质量(长度,完整性,多样性)、检索器的精度(速度与精度之间的取舍)。与数据质量对应的就是检索词的质量。
检索器的精度比较容易解决,向量模型的训练略复杂,因此数据和检索词质量优化成了一个重要的环节。
提高向量搜索精度的方法
- 更好分词分段:当一段话的结构和语义是完整的,并且是单一的,精度也会提高。因此,许多系统都会优化分词器,尽可能的保障每组数据的完整性。
- 精简
index的内容,减少向量内容的长度:当index的内容更少,更准确时,检索精度自然会提高。但与此同时,会牺牲一定的检索范围,适合答案较为严格的场景。 - 丰富
index的数量,可以为同一个chunk内容增加多组index。 - 优化检索词:在实际使用过程中,用户的问题通常是模糊的或是缺失的,并不一定是完整清晰的问题。因此优化用户的问题(检索词)很大程度上也可以提高精度。
- 微调向量模型:由于市面上直接使用的向量模型都是通用型模型,在特定领域的检索精度并不高,因此微调向量模型可以很大程度上提高专业领域的检索效果。
FastGPT 构建知识库方案
数据存储结构
在 FastGPT 中,整个知识库由库、集合和数据 3 部分组成。集合可以简单理解为一个文件。一个库中可以包含多个集合,一个集合中可以包含多组数据。最小的搜索单位是库,也就是说,知识库搜索时,是对整个库进行搜索,而集合仅是为了对数据进行分类管理,与搜索效果无关。(起码目前还是)
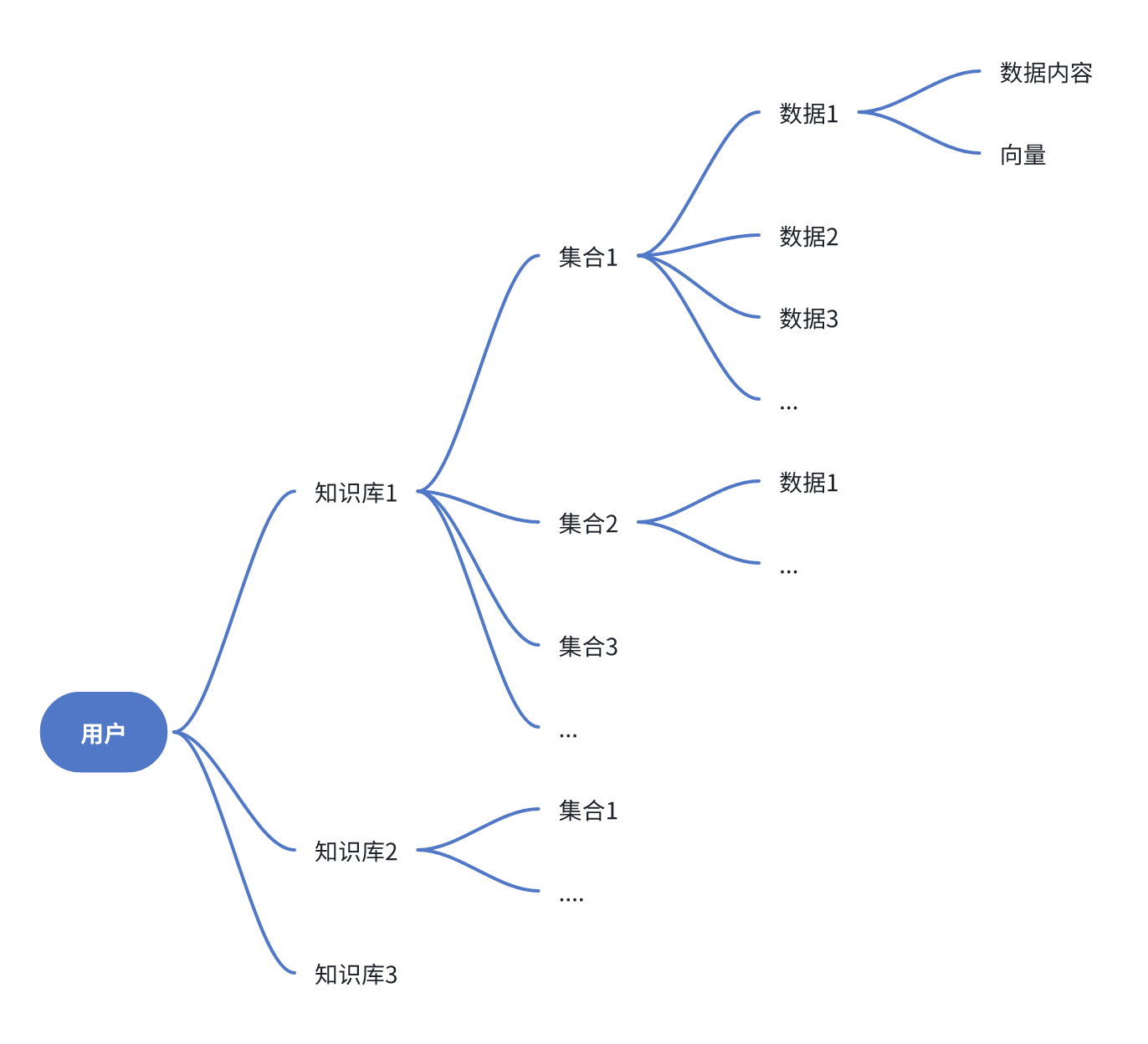
向量存储结构
FastGPT 采用了PostgresSQL的PG Vector插件作为向量检索器,索引为HNSW。且PostgresSQL仅用于向量检索(该引擎可以替换成其它数据库),MongoDB用于其他数据的存取。
在MongoDB的dataset.datas表中,会存储向量原数据的信息,同时有一个indexes字段,会记录其对应的向量ID,这是一个数组,也就是说,一组向量可以对应多组数据。
在PostgresSQL的表中,设置一个vector字段用于存储向量。在检索时,会先召回向量,再根据向量的ID,去MongoDB中寻找原数据内容,如果对应了同一组原数据,则进行合并,向量得分取最高得分。
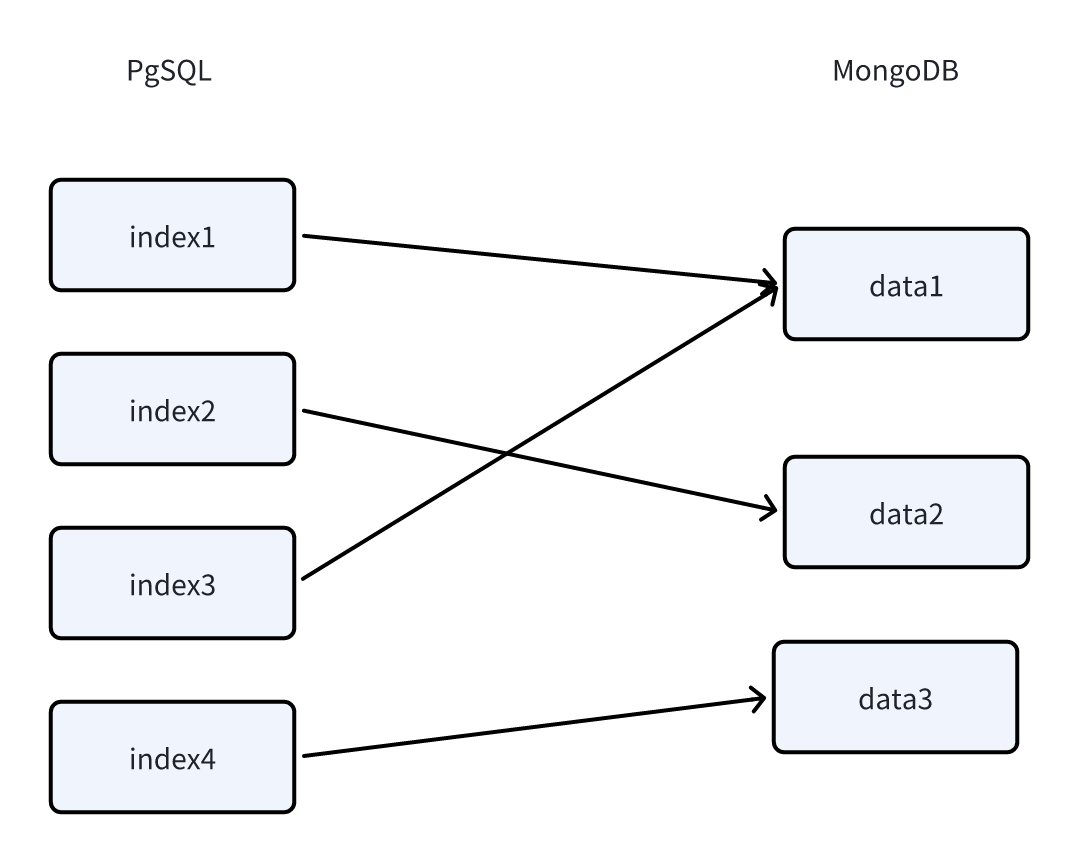
多向量的目的和使用方式
在一组向量中,内容的长度和语义的丰富度通常是矛盾的,无法兼得。因此,FastGPT 采用了多向量映射的方式,将一组数据映射到多组向量中,从而保障数据的完整性和语义的丰富度。
你可以为一组较长的文本,添加多组向量,从而在检索时,只要其中一组向量被检索到,该数据也将被召回。
意味着,你可以通过标注数据块的方式,不断提高数据块的精度。
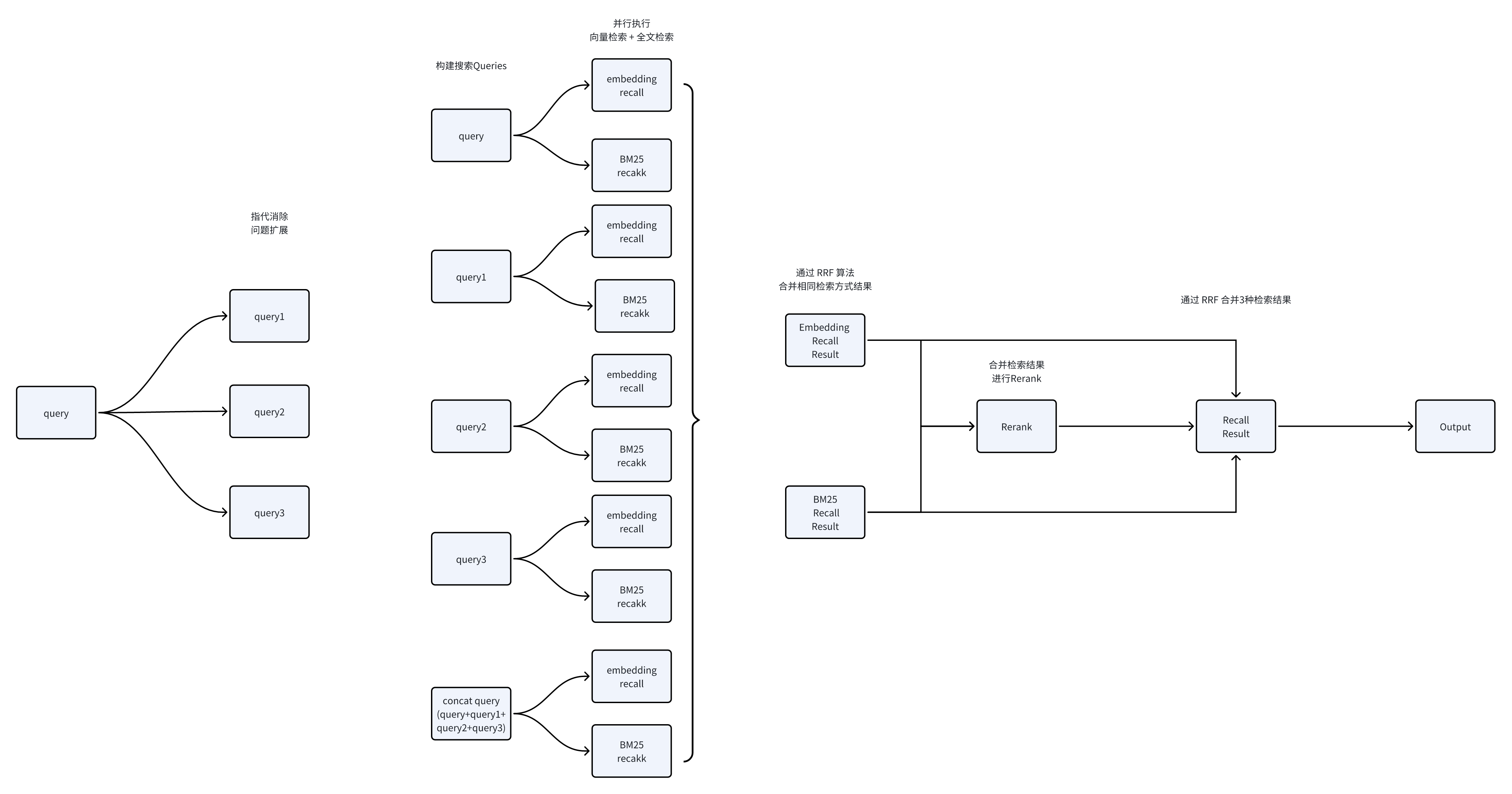
检索方案
- 通过
问题优化实现指代消除和问题扩展,从而增加连续对话的检索能力以及语义丰富度。 - 通过
Concat query来增加Rerank连续对话的时,排序的准确性。 - 通过
RRF合并方式,综合多个渠道的检索效果。 - 通过
Rerank来二次排序,提高精度。
搜索参数
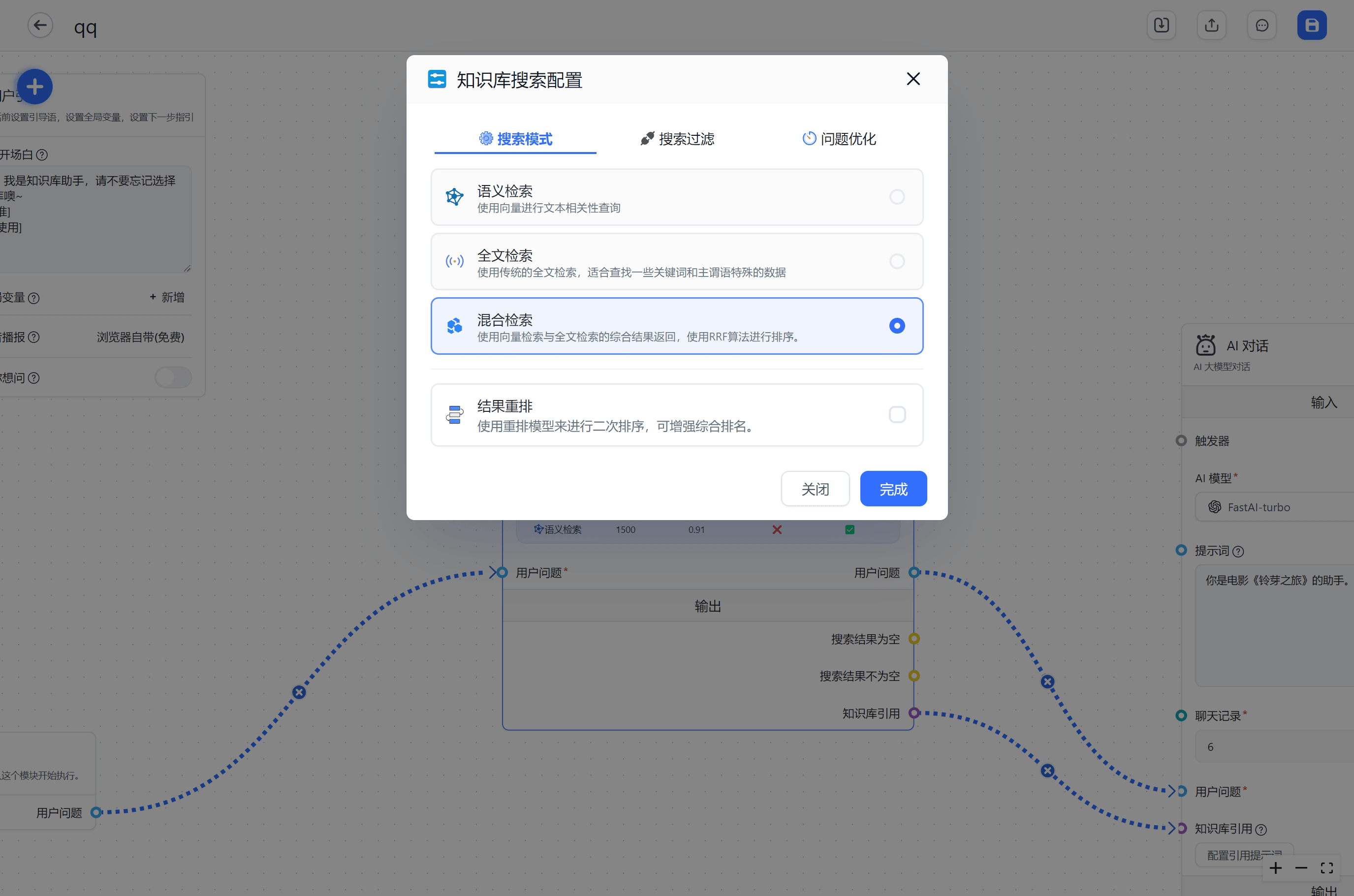 |  | 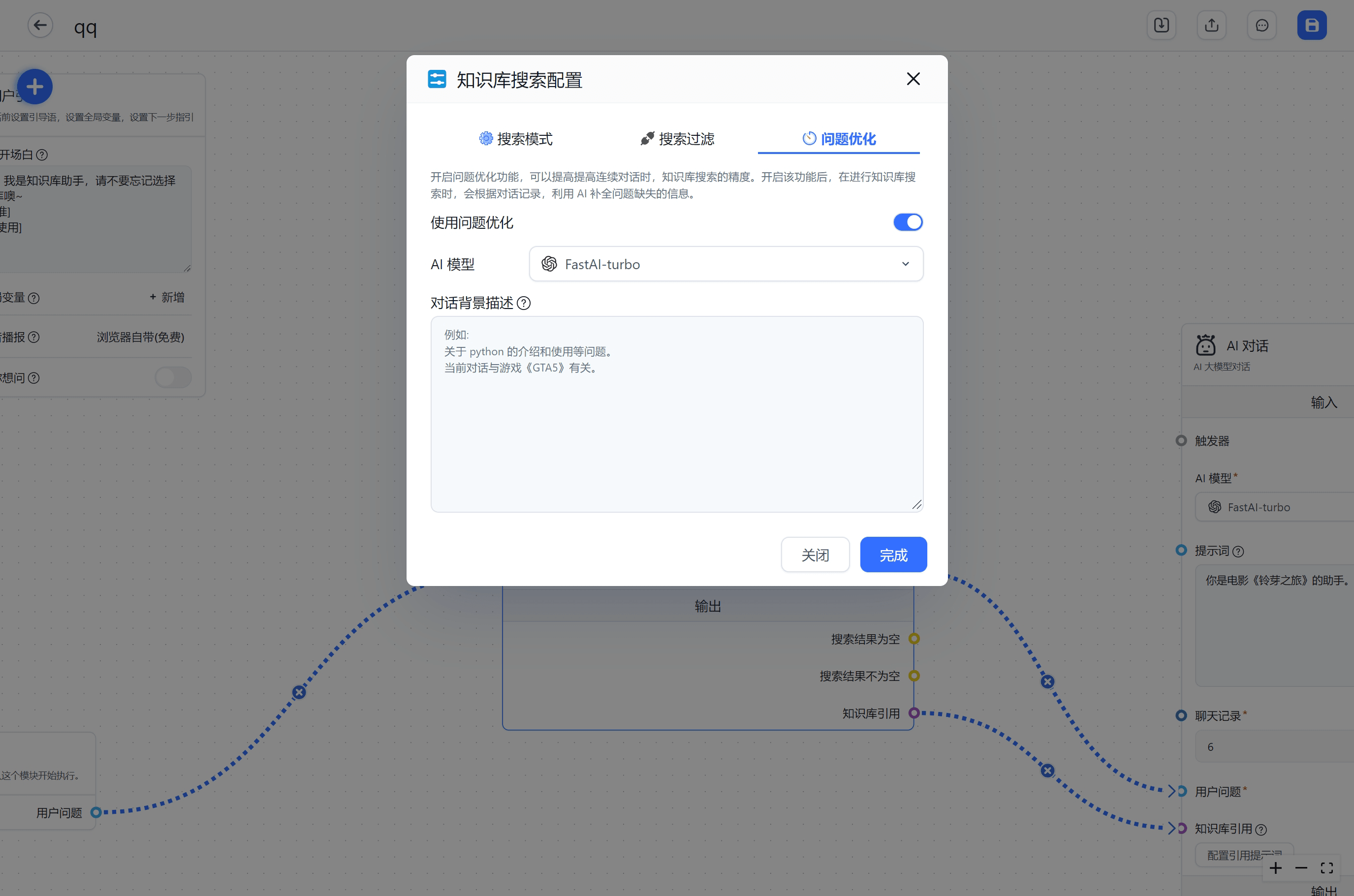 |
搜索模式
语义检索
语义检索是通过向量距离,计算用户问题与知识库内容的距离,从而得出“相似度”,当然这并不是语文上的相似度,而是数学上的。
优点:
- 相近语义理解
- 跨多语言理解(例如输入中文问题匹配英文知识点)
- 多模态理解(文本,图片,音视频等)
缺点:
- 依赖模型训练效果
- 精度不稳定
- 受关键词和句子完整度影响
全文检索
采用传统的全文检索方式。适合查找关键的主谓语等。
混合检索
同时使用向量检索和全文检索,并通过 RRF 公式进行两个搜索结果合并,一般情况下搜索结果会更加丰富准确。
由于混合检索后的查找范围很大,并且无法直接进行相似度过滤,通常需要进行利用重排模型进行一次结果重新排序,并利用重排的得分进行过滤。
结果重排
利用ReRank模型对搜索结果进行重排,绝大多数情况下,可以有效提高搜索结果的准确率。不过,重排模型与问题的完整度(主谓语齐全)有一些关系,通常会先走问题优化后再进行搜索-重排。重排后可以得到一个0-1的得分,代表着搜索内容与问题的相关度,该分数通常比向量的得分更加精确,可以根据得分进行过滤。
FastGPT 会使用 RRF 对重排结果、向量搜索结果、全文检索结果进行合并,得到最终的搜索结果。
搜索过滤
引用上限
每次搜索最多引用n个tokens的内容。
之所以不采用top k,是发现在混合知识库(问答库、文档库)时,不同chunk的长度差距很大,会导致top k的结果不稳定,因此采用了tokens的方式进行引用上限的控制。
最低相关度
一个0-1的数值,会过滤掉一些低相关度的搜索结果。
该值仅在语义检索或使用结果重排时生效。
问题优化
背景
在 RAG 中,我们需要根据输入的问题去数据库里执行 embedding 搜索,查找相关的内容,从而查找到相似的内容(简称知识库搜索)。
在搜索的过程中,尤其是连续对话的搜索,我们通常会发现后续的问题难以搜索到合适的内容,其中一个原因是知识库搜索只会使用“当前”的问题去执行。看下面的例子:
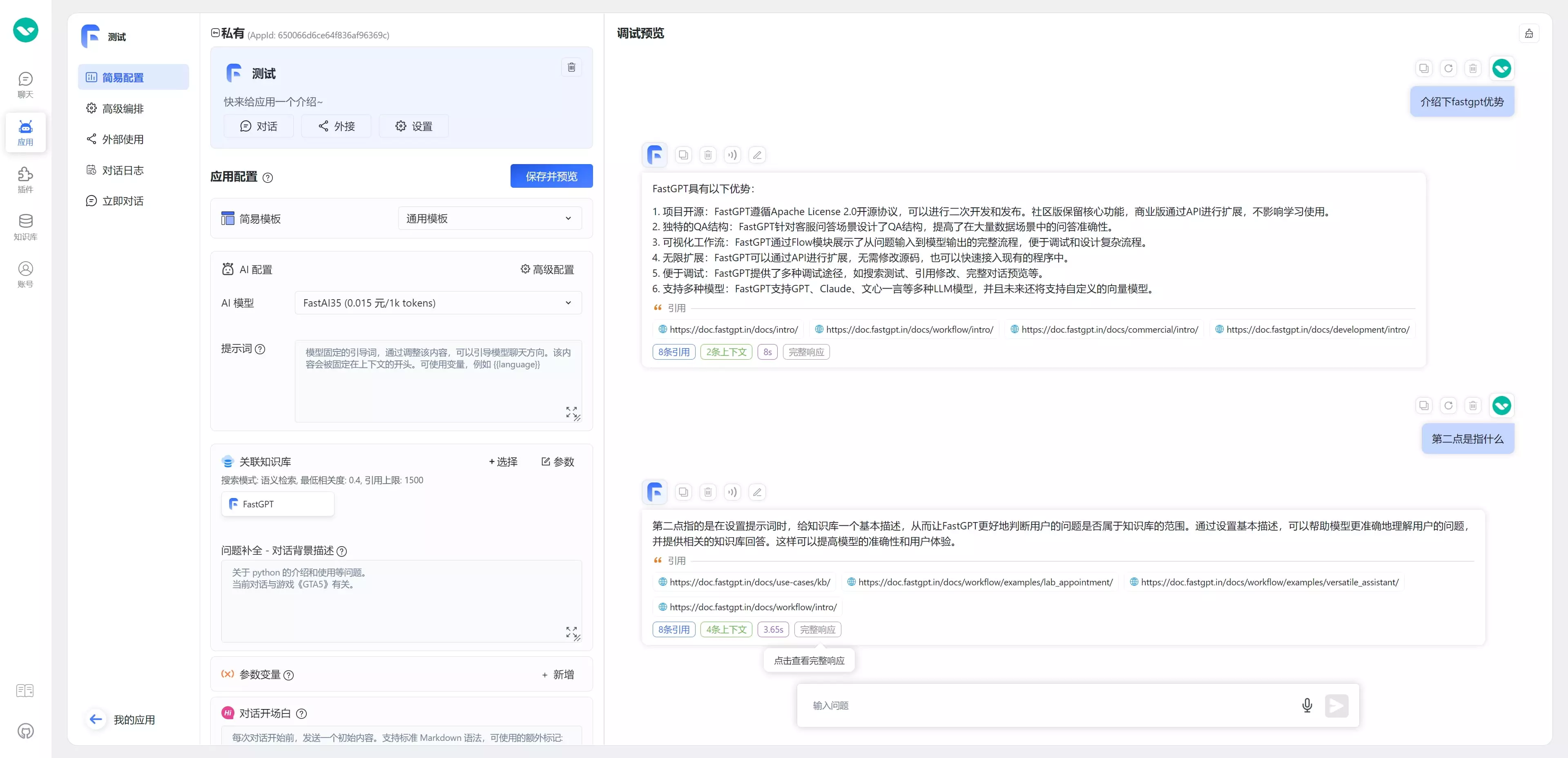
用户在提问“第二点是什么”的时候,只会去知识库里查找“第二点是什么”,压根查不到内容。实际上需要查询的是“QA结构是什么”。因此我们需要引入一个【问题优化】模块,来对用户当前的问题进行补全,从而使得知识库搜索能够搜索到合适的内容。使用补全后效果如下:
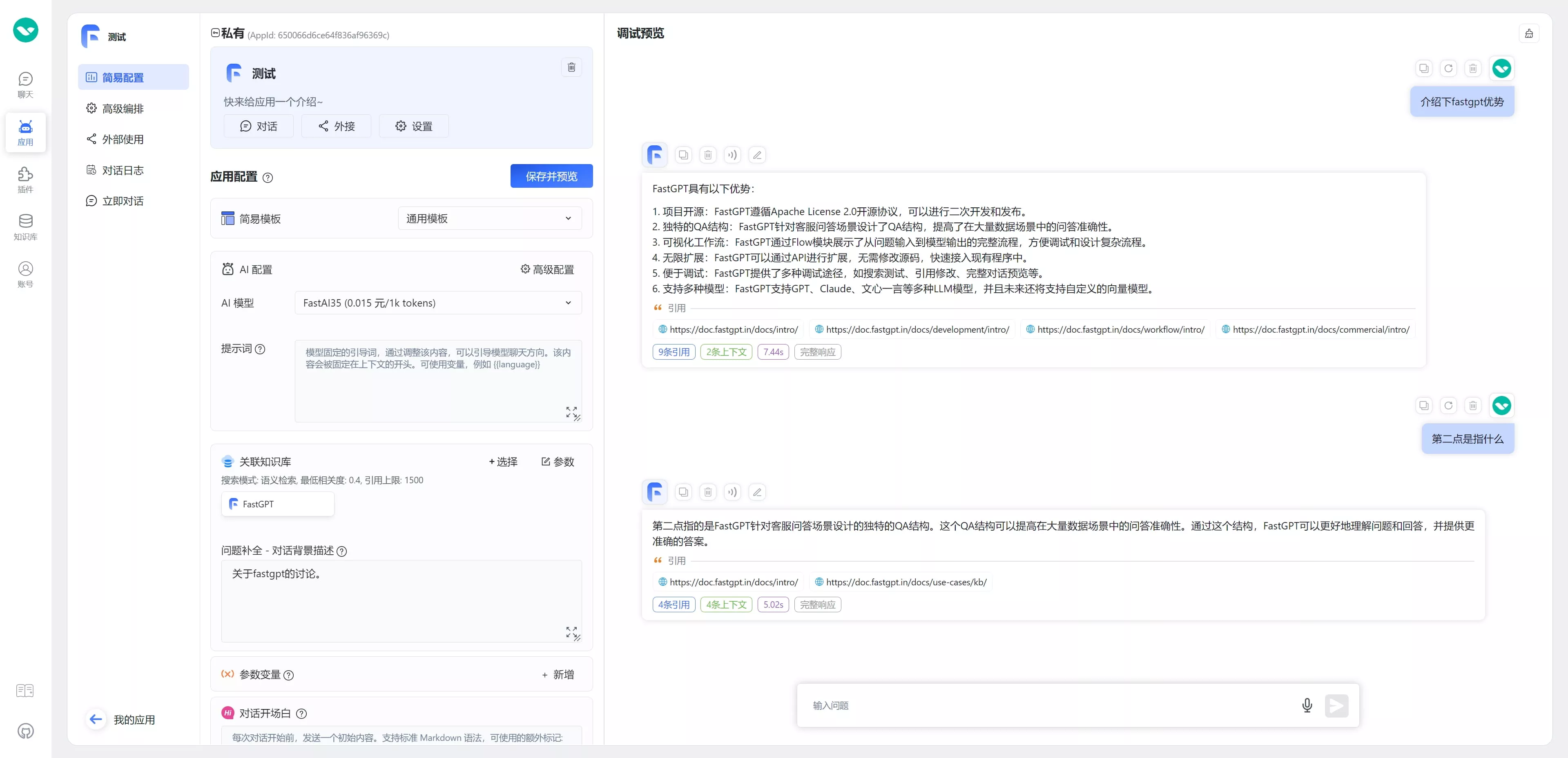
实现方式
在进行数据检索前,会先让模型进行指代消除与问题扩展,一方面可以可以解决指代对象不明确问题,同时可以扩展问题的语义丰富度。你可以通过每次对话后的对话详情,查看补全的结果。