接入 ChatGLM2-6B
将 FastGPT 接入私有化模型 ChatGLM2-6B
前言
FastGPT 允许你使用自己的 OpenAI API KEY 来快速调用 OpenAI 接口,目前集成了 GPT-3.5, GPT-4 和 embedding,可构建自己的知识库。但考虑到数据安全的问题,我们并不能将所有的数据都交付给云端大模型。
那么如何在 FastGPT 上接入私有化模型呢?本文就以清华的 ChatGLM2 为例,为各位讲解如何在 FastGPT 中接入私有化模型。
ChatGLM2-6B 简介
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,具体介绍可参阅 ChatGLM2-6B 项目主页。
注意,ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。本教程只是介绍了一种用法,无权给予任何授权!
推荐配置
依据官方数据,同样是生成 8192 长度,量化等级为 FP16 要占用 12.8GB 显存、int8 为 8.1GB 显存、int4 为 5.1GB 显存,量化后会稍微影响性能,但不多。
因此推荐配置如下:
| 类型 | 内存 | 显存 | 硬盘空间 | 启动命令 |
|---|---|---|---|---|
| fp16 | >=16GB | >=16GB | >=25GB | python openai_api.py 16 |
| int8 | >=16GB | >=9GB | >=25GB | python openai_api.py 8 |
| int4 | >=16GB | >=6GB | >=25GB | python openai_api.py 4 |
部署
环境要求
- Python 3.8.10
- CUDA 11.8
- 科学上网环境
源码部署
- 根据上面的环境配置配置好环境,具体教程自行 GPT;
- 下载 python 文件
- 在命令行输入命令
pip install -r requirements.txt; - 打开你需要启动的 py 文件,在代码的
verify_token方法中配置 token,这里的 token 只是加一层验证,防止接口被人盗用; - 执行命令
python openai_api.py --model_name 16。这里的数字根据上面的配置进行选择。
然后等待模型下载,直到模型加载完毕为止。如果出现报错先问 GPT。
启动成功后应该会显示如下地址:

这里的
http://0.0.0.0:6006就是连接地址。
docker 部署
镜像和端口
- 镜像名:
stawky/chatglm2:latest - 国内镜像名:
registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/chatglm2:latest - 端口号: 6006
# 设置安全凭证(即oneapi中的渠道密钥)
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
也可以通过环境变量引入:sk-key。有关docker环境变量引入的方法请自寻教程,此处不再赘述。
接入 One API
为 chatglm2 添加一个渠道,参数如下:
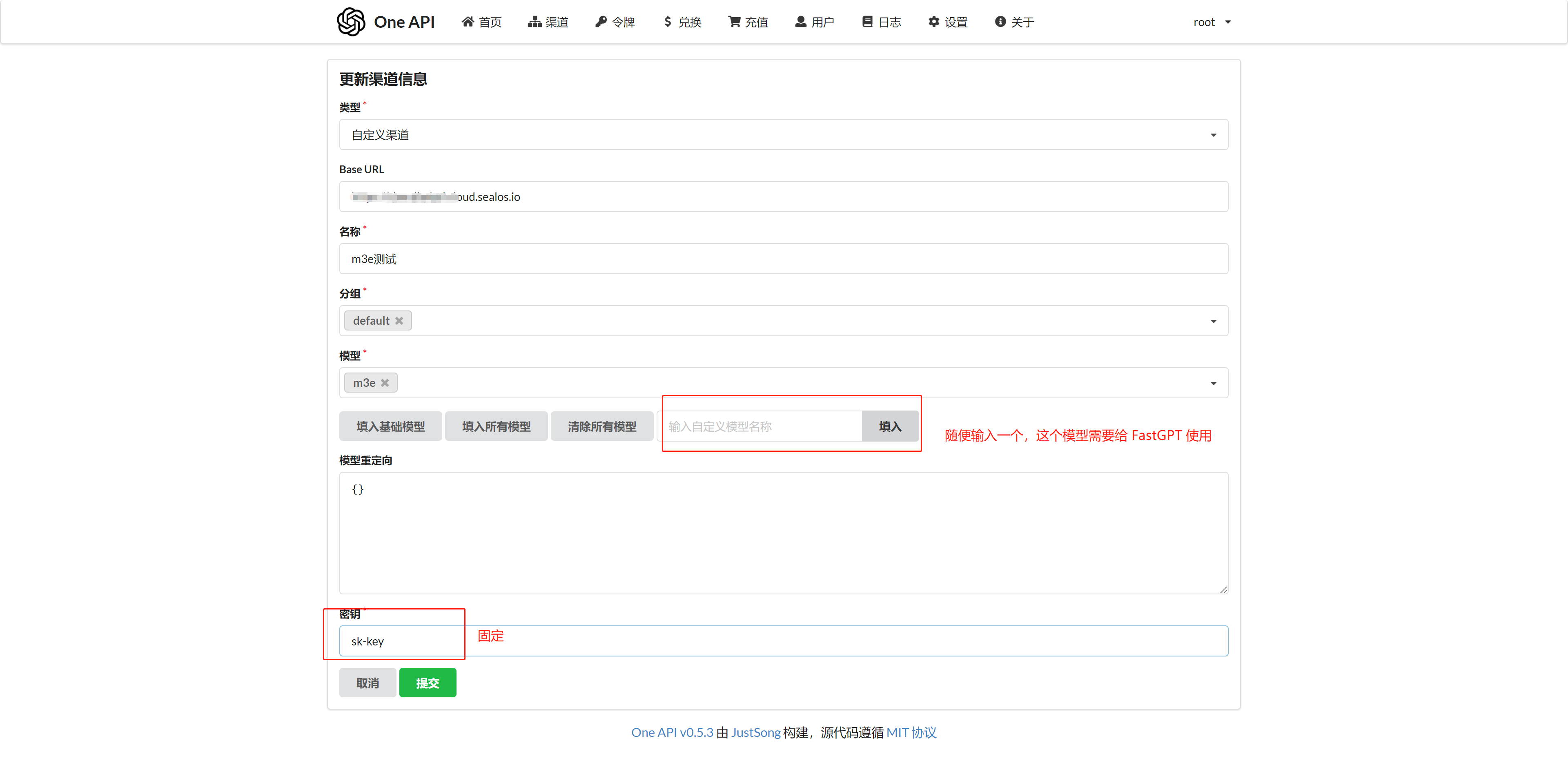
这里我填入 chatglm2 作为语言模型
测试
curl 例子:
curl --location --request POST 'https://domain/v1/chat/completions' \
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "chatglm2",
"messages": [{"role": "user", "content": "Hello!"}]
}'
Authorization 为 sk-aaabbbcccdddeeefffggghhhiiijjjkkk。model 为刚刚在 One API 填写的自定义模型。
接入 FastGPT
修改 config.json 配置文件,在 llmModels 中加入 chatglm2 模型:
"llmModels": [
//已有模型
{
"model": "chatglm2",
"name": "chatglm2",
"maxContext": 4000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1,
"vision": false,
"defaultSystemChatPrompt": ""
}
]
测试使用
chatglm2 模型的使用方法如下:
模型选择 chatglm2 即可